The Nature paper Efficient evolution of human antibodies from general protein language models has already made the rounds, and deservingly so: it shows an elegant and practical method to speed-up iterative protein design in a way that's impressively effective and most likely very useful. But it's worth taking a deeper look not at how it works but at why it works, which is something is seldom asked in practical applications — and, to be fair, we don't fully understand yet for many or most models in many or most settings — but can be the difference between failure and success.
I encourage you to read the paper, which is open access, but to our purposes (not, it must be emphasized, if you're explaining the work itself in its domain context) we can describe what they did as training a language model on a data set of natural protein sequences, sampling from it to suggest mutations for an iterative antibody improvement loop. And it worked! Antibodies improved much faster (i.e. with fewer trials and cycles) than with other baseline methods.
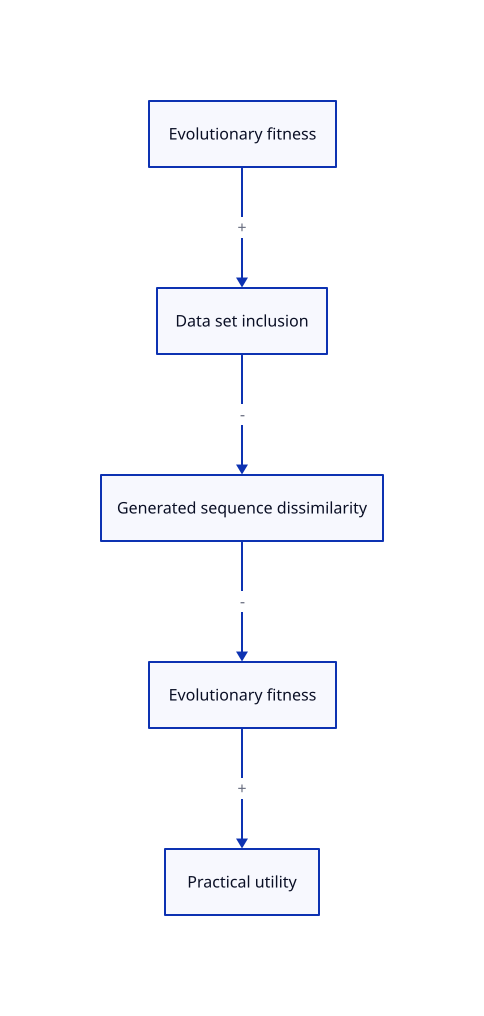
The paper also gives a good explanation about their thinking process. If you only have a few minutes (but you should use more), you can start with Fig 1 in the paper — I put here a cropped version purely for aesthetic purposes. Their hypothesis was that evolutionary pressures favor protein characteristics that are useful in application settings, which means that sampling from evolutionary plausible mutations would favor high-utility proteins.
This is a very neat idea! It pays, though, to try to clarify this even more — there's much here that's assumed or implied in domain knowledge or elsewhere in the paper, and translating this idea elsewhere benefits from understanding each individual step.
The first thing to note: it's a data set of natural protein sequences, which means — this sounds pedantic, but is critical — that presence in the data set is positively correlated with evolutionary fitness.
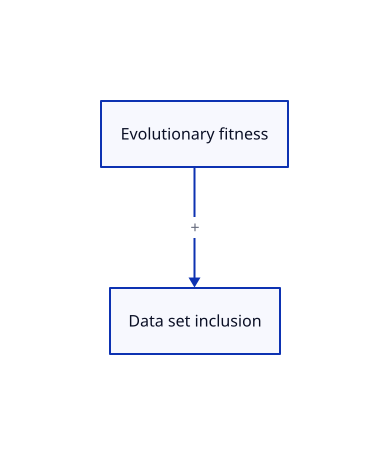
To keep being obvious: data set inclusion is negatively correlated with distance with generated sequences, for some concept of distance that's specific to the model training method. This is what sampling from a model means.
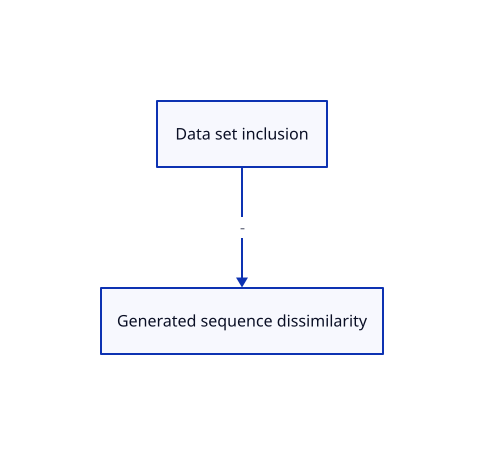
Now, the usual, unexpressed, assumption is that a bias in a data set will induce the same bias in the generated samples. This is a natural assumption: after all, most of the cases of bias in sample generation (like images of CEOs tending to be middle-aged white males) come from bias in the data set (like most CEOs being middle-aged white males...). But it's not necessarily true: depending on the way the algorithm was trained, it might "respect" or not any bias in the data.
So much for technical assumptions. There's a biological one that's also necessary: that evolutionary fitness is positively correlated with usefulness. That's an explicit part of the paper's hypothesis, but not something you can blindly assume in general. Trying to optimize proteins using a generative model trained on natural protein sequences might work out very badly if your goal is performance in non-biological environments!
In a less scientific context, consider attempting to create a system to generate innovative movie ideas, or web designs, or anything like that. Training a generative model with a large data set of existing examples and the using it to guide an iterative optimization model is a very 2023 thing to attempt, but chances are your data set will be biased towards non-innovative movies (many of those for each innovative one), or, in other words, the equivalent of evolutionary fitness is just the ability of a movie to be made so your final system will be much more conservative than you want, and will keep pulling you toward the same old ideas.
So you very much need
Putting everything together, the idea of the original paper's team works because all of the following work out correctly so at the end generated sequences (with low dissimilarity to the data set) are likely to have high utility:
One one hand, this is a very primitive sort of analysis; you can sketch it in fifteen minutes, add some mathematical details in a couple of hours and search the literature or even do a couple of quick checks of key steps in a couple of days. It's not something you write a blog post or give a talk about.
On the other hand, I've seen more than one long and expensive failure that would have been prevented with those fifteen minutes' worth of sketching (whether or not internal corporate culture made it possible to acknowledge their failure). Modeling and engineering are how we build systems that take advantage of these information flows and relationships, but nothing comes from nothing. No amount of AI magic will give you improvements on any metrics unless relevant information is flowing from somewhere,: data set biases, your regularization scheme, external rules, experimentation, etc. Fifteen minutes making sure you understand where that information is meant to come from — and checking against your experience and other experts' knowledge how likely that seems — can help a company avoid or fix otherwise doomed projects even before writing the first slide for the first kickoff meeting.
Perhaps more importantly, once a company or a group starts thinking in this way it clarifies many general processes that go far beyond the original project; it's probably a prerequisite, and it's certainly a facilitator, for the AI-ready or even just the data-driven organization.