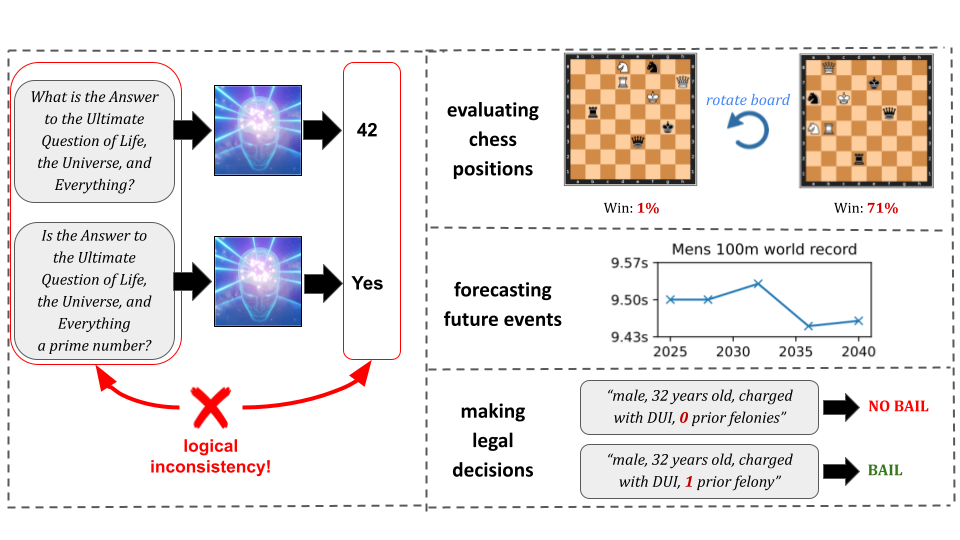
Here's a paper (and repo) from the SPY Lab at ETH Zürich with a clever approach at evaluating superhuman AI performance in contexts where you don't necessarily have a clear ground truth, like games. The key idea is that even if the program is better than you at something, you can check some consistency rules it has to follow no matter how smart. For example, if two chess positions are mirrored, the value of each pair of mirrored moves should be exactly the same, or if a model evaluates the probability of something happening at 60%, it should evaluate the probability of it not happening at 40%. Basic things like that.
Yet (otherwise superhuman) AIs do get it wrong! Infrequently in things like chess, but ask a large language model the probability of something happening, and then ask the same thing in a slightly different way, and you can get wildly inconsistent answers.
This is essentially unsurprising: LLMs are linguistic models. They are optimized for linguistic plausibility, not for whatever domain you are asking about. They don't know what they are talking about - all they know about is the talking. Yet people forget — or, when convenient, pretend to forget — that isn't the case, and attempt to deploy cheap and impressive but inherently, irreparably flaky generic models in fields where superhuman reliability is just as important as superhuman capability.