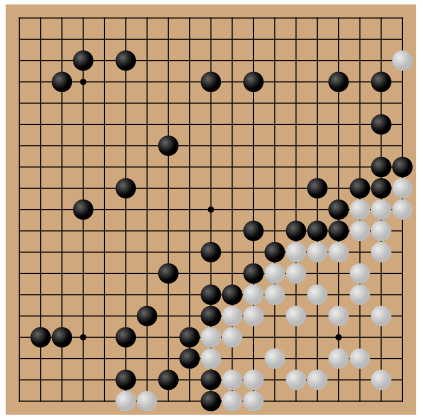
The most interesting AI paper in a while is the recent Adversarial Policies Beat Professional-Level Go AIs. The site, and even the paper alone, gives very comprehensive details and examples, but I wanted to do a quick analysis of what they built, why it matters, and what's the open question.
In short, they built the strategic equivalent of the typical adversarial attack on an image classifier: a system that plays in a way that humans can easily defeat but that KataGo, at the moment the strongest open Go player (and indeed a superhuman one), loses against. It wins not by playing a good strategy in the general sense, but one that creates a very narrow set of situations where KataGo makes an immediately fatal move (passing when it shouldn't).
Four things of note, in sequence:
- The researchers didn't identify weakness in KataGo and built a system to exploit it.
- Instead, they trained a system by playing it against KataGo until it found way to win.
- It's a very specific predator: it loses against very bad human players and other AIs.
- Adding a hand-crafted "fix" to the vulnerability makes KataGo defeat the new system consistently.
None
Some practical takeaways:
- Perhaps adversarial training of this sort should be an standard phase of AI training. Anything that people will want to make fail will eventually be subject to this sort of attack, so you might as well do it first and see what you can find.
- Anything you don't want your AI to do, ever, you have to code, not train.
- The researchers didn't need access to the parameters of KataGo, only the ability to play against it. Security through obscurity doesn't work here either.
None
And some questions and hypothesis:
- I suspect that neuro-symbolic (or otherwise partially low-dimensional) models will show an stronger relationship between capabilities and robustness, and that this is a vulnerability inherent to this sort of model, but I'm not sure.
- I'm not even sure that there's always a vulnerability of this sort in any trained model. E.g., say we retrain KataGo in a way that accounts for this adversarial attack - would we able to find another attack of the same sort? How many rounds of this would take until we can't? My gut feeling is that finding this sort of failure model will always be possible in models with huge parameter spaces, but with exploding and soon impractical costs. The longer this isn't true, the more interesting this finding becomes not from the point of view of AI engineering but from the point of view of cognitive engineering, because you'd be saying that every program that can play well enough a complex-enough game will have failure modes exploitable by specifically trained but otherwise weak opponents.
- For "game" you can also read "any sufficiently interesting applications."
- No this has nothing to do with Gödel, please don't go there.
In short: This paper shows non-transitivity in play skill involving a generally superhuman player, which is of immediate practical interest to anybody building or trying to defeat one, so, basically, everybody.
(Image taken from the paper site, https://goattack.alignmentfund.org/)